Looking after your data is crucial to maintaining a healthy relationship with your users. For example, bombarding them on a daily basis is likely to alienate them, lead to an increase in unsubscribes and produce more complaints all potentially damaging your reputation in the long run. One example where this may be tricky to manage is for agencies that divvy out their data from the same pool to lots of different clients. Clients don’t care about other clients, they just want their campaigns to go ASAP.
So, for a situation such as this one thing you can do is be proactive with your scheduling to try to ensure that users will receive emails as many days apart as possible to prevent or minimise this potential alienation. Obviously when slicing your data up being aware beforehand of the schedule would be useful in allowing you to segment the data with duplicates in mind, but this may not always be possible. If, for example, you are restrained by specific targeting and forced to use the same pots of data for multiple lists then knowing how many repeat emails there are that appear across the different datasets could be helpful in setting the schedule.
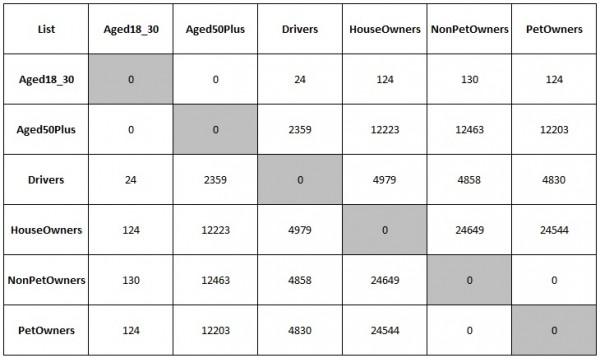
Imagine you had 6 different lists but you had no idea how many duplicate emails appeared across them all:
MySQL Table Name
Aged18_30
Aged50Plus
Drivers
HouseOwners
NonPetOwners
PetOwners
You don’t want to have to join each table in turn to establish how many duplicates there are across every permutation as that would be tedious and time wasting. Instead, you can utilise the following MySQL stored procedure which simply requires the list of your table names (i.e. in a SQL table named List_Names with one field labelled ListName) and will cycle round and add up all the duplicates for you.
CREATE PROCEDURE sp_DedupeAnalysis (OUT Results varchar (200))
NOT DETERMINISTIC
CONTAINS SQL
BEGIN
/*Declare your variables*/
declare sqlexec varchar(10000);
declare Counter int;
declare LoopCounter int;
declare LoopCounter2 int;
declare FieldName varchar(200);
declare RowName varchar(200);
declare ColumnID int;
set ColumnID = 1;
set Counter = (select max(ID) from List_Names);
set LoopCounter = 1;
/*Create the column names for the final output table by using the SQL table names and cycling round for as many as there are*/
drop table if exists DedupeAnalysis
;
set sqlexec = concat("create table DedupeAnalysis (List varchar(200),");
WHILE LoopCounter < Counter DO
BEGIN
set FieldName = (select ListName from List_Names where ID = LoopCounter);
set sqlexec = concat(sqlexec,FieldName," varchar(200),");
set LoopCounter = LoopCounter+1;
END;
END WHILE;
IF LoopCounter = Counter THEN
set FieldName = (select ListName from List_Names where ID = LoopCounter);
set sqlexec = concat(sqlexec,FieldName," varchar(200))");
END IF;
select sqlexec into @Results;
prepare stmt from @Results;
execute stmt;
/*Create the row names for the final output table by inserting the SQL table names*/
insert into DedupeAnalysis
(List)
select ListName from List_Names
;
/*Update every cell of the table by selecting the first table name, and running the join counts for all other tables against it before updating the table DedupeAnalysis. LoopCounter selects the current row and LoopCounter2 selects the columns.*/
set LoopCounter = 1;
WHILE ColumnID <= Counter DO
BEGIN
set FieldName = (select ListName from List_Names where ID = LoopCounter);
set LoopCounter2 = 1;
WHILE LoopCounter2 <= Counter DO
BEGIN
set RowName = (select ListName from List_Names where ID = LoopCounter2);
IF FieldName=RowName THEN
set sqlexec = concat("update DedupeAnalysis set ",FieldName," = 0 where List = '",RowName,"'");
select sqlexec into @Results;
prepare stmt from @Results;
execute stmt;
ELSE
set sqlexec = concat("update DedupeAnalysis set ",FieldName," = (select count(*) from ",FieldName," a inner join ",RowName," b on a.email = b.email) where List = '",RowName,"'");
select sqlexec into @Results;
prepare stmt from @Results;
execute stmt;
END IF;
set LoopCounter2 = LoopCounter2+1;
END;
END WHILE;
set LoopCounter = LoopCounter+1;
set ColumnID = ColumnID+1;
END;
END WHILE;
/*Output the table*/
select * from DedupeAnalysis
;
END
GO
So, once you’ve got your table List_Names in SQL simply run:
CALL sp_DedupeAnalysis (@Results)
;
You’ll then get a nice reference table output which will allow you to see how many emails match between any two different datasets which, for this example, should help with scheduling decisions in order to keep those with the most crossover as far apart as possible, plus there are probably many other scenarios where knowing the crossover between multiple datasets could be useful.